
Hello and welcome! I’m excited to share a recent side project I completed, a personalized recipe recommendation engine leveraging the ratings of 225k recipes, 200k users, and 1.1 million reviews on Food.com. As someone who has a passion for food, data analytics, and building products to solve problems, I was excited to be able to use machine learning to take an idea I had and turn it into a basic prototype. This project leveraged previous knowledge I had of Python and machine learning but took me on a path to build news skills in design thinking, Apache Spark, model tuning, and alternating least squares algorithms.
Mapping the Customer Journey
I conducted several research methods to dive into the key needs and desires of grocery store customers and guide my solution. I meticulously analyzed the grocery shopping experience in-person and on the web, observing the store’s intentions with how they crafted each part of the experience. I interviewed grocery store customers, taking note of their experience journey from deciding to go to the grocery store, through their time in the store, and back home. This process analyzed not only what customers did but also why they did it. Why did they go to a specific store even during rush hour traffic? Why did they spend so much time wandering around the grocery store? I would then look for ways to eliminate or address these underlying needs.
Convenience emerges as a major factor
Through this research, a common theme that emerged was the importance of convenience in the grocery shopping experience. Customer grocery experiences were heavily influenced by convenience (how far they had to drive, could they get all their items at one place, etc.), and popular grocers were taking actions targeting this desire (grocery delivery, pre-made meals, large item selection, etc.). This finding was complemented by a quantitative conjoint analysis that emphasized convenience as a significant factor in shopping preferences. As a result, convenience would be the core pillar of my solution, where any solution would need to answer yes to the question of “Does this enhance the user experience by enabling them to complete their shopping more conveniently?”
The growing popularity of recommendation engines
From a 2013 McKinsey study, 35% of Amazon purchases and 75% of what users watch on Netflix comes from product recommendations, and I’m sure this number has only continued to grow. These findings would inspire the idea of a recipe recommendation engine, leveraging the shoppers unique “taste profile”, aimed at simplifying the meal planning and grocery shopping experience. In theory, grocers could use such an engine to recommend recipes to users based on their purchase history and ratings to speed up the shopping experience and provide value.
How It Works
From a high level, the engine works by starting with a quick get-to-know-you onboarding session to get some initial data on your culinary preferences. From here, the model looks at 200,000 other users and uses the favorite recipes of users with similar taste profiles to fuel the recommendations given to you!
It’s a similar concept to if you and your friend enjoyed the same type of music, you’d listen to their song recommendations because if they liked a song there’s a good chance you would too! From there, the recommendation system evolves as you try recipes and give ratings, helping it pinpoint exactly what you like.
Let’s see it in action!
First, we’ll go through a brief new user onboarding to indicate some initial preferences. This user receives their User ID, and then tells the model they especially like non-spicy American, Italian, and Barbecue recipes that they can make in under an hour.

Nice! With the user providing this data, the trained model generates some initial recipe recommendations based on highly rated recipes of users with similar taste profiles. The user can browse the options and go straight to the full recipe on food.com!
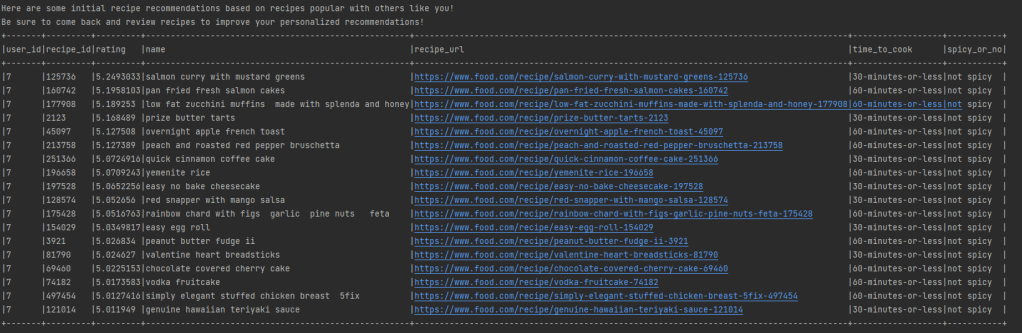
When the user wants more recipe recommendations or to rate a recipe, they can return to the recommendation engine. By entering their unique user id, the model will hone in on the user’s unique taste profile. This user thought the pan-fried salmon cakes (recipe ID: 160742) were pretty good and gives it a rating. By leaving ratings, the engine is able to further refine the user’s taste profile and improve the quality of its recommendations.

From here, the user selects culinary preferences for this batch of recommendations. This time they care how long the recipe takes to cook, as long as it’s not spicy!

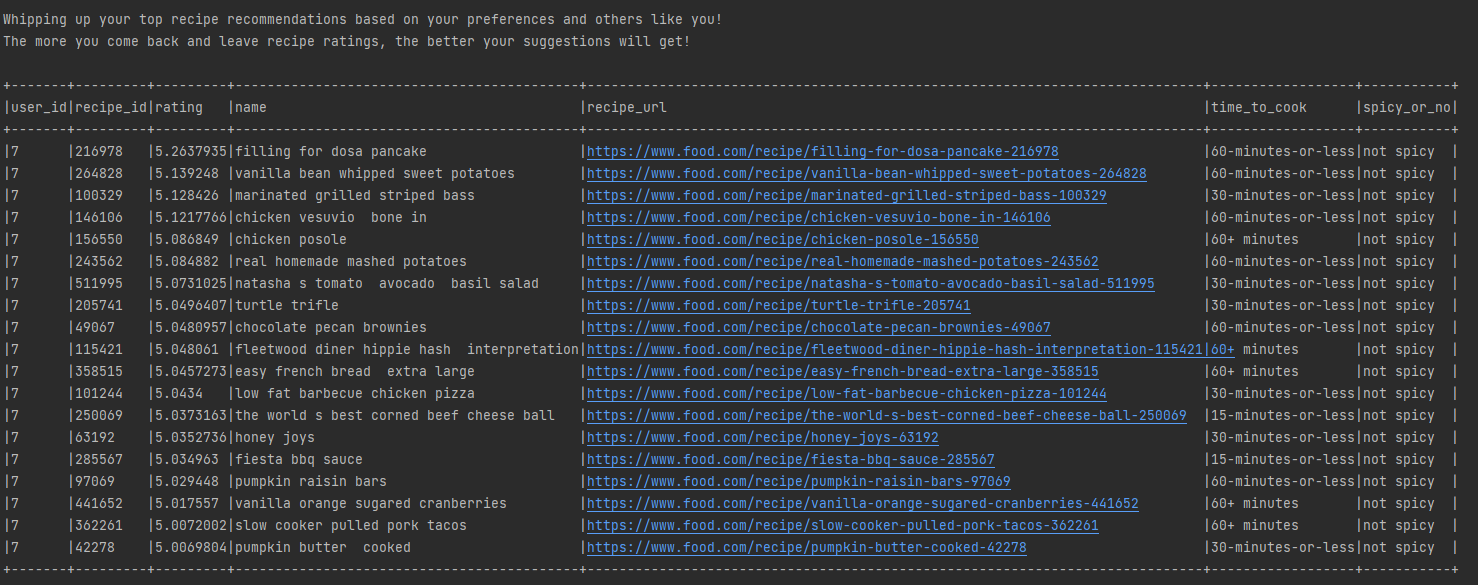
Now we get another round of recipe suggestions! The more reviews the user leaves, the more accurate the model will be at crafting their taste profile and the better the recipe suggestions will be.
Overcoming Technical Challenges
Integrating Apache Spark
Building the recommendation engine certainly had its challenges, particularly in managing and processing the large dataset. My initial attempts overwhelmed basic machine learnings tool. With 225,000 recipes and 200,000 users, I needed something capable of handling the data fueling the engine. This led to the adoption of Apache Spark’s PySpark API, with distributed computing and machine learning libraries able to help me scale the model. Additionally, I needed an algorithm that could take advantage of distributing computing, handle sparse matrices, and effectively incorporate user-recipe interactions to make predictions, this is where I landed on the Alternating Least Squares algorithm.
Optimizing for RMSE
After cleaning the data, training and tuning the model using cross validation with a series of different hyperparameters (i.e., model settings), the model had a root mean squared error (RMSE) of 0.794. This meant that the model’s predicted score for what a user would rate a recipe was about 0.80 off of what the user actually rated the recipe.
I found that recipes with a low number of reviews simply had too small a sample size for the model to understand which types of taste profiles would enjoy them best. As a result, I filtered out recipes with less than 5 reviews, leaving the recipe bank at a still sizeable 51,000. With this final dataset the model landed at an RMSE of 0.685. There are certainly ways to improve this metric in future versions of the model.
Beyond the Prototype: Future Improvements
While this first prototype addressed the basic goal of the recommendation engine, the accuracy of the recommendations and user experience can definitely be improved. Some ideas include:
| Future Improvement | Benefit | Possible Implementation Strategy |
| Web interface with account creation | Users won’t need to remember their user IDs or IDs of recipes they want to rate | Bootstrap webpage or no/low code app like FlutterFlow |
| Integrate additional features into model | Better, more accurate predictions and suggestions | The number of ingredients, cooking techniques required, how recently the user cooked that type of cuisine, weather API (ex: suggest hot food when it’s cold outside) |
| Have the user indicate which recipes they want to check out from the suggestions table and receive emails with links | Better user experience, can easily look at recipes later | Require additional inputs to select recipes from final suggestions table and use Python’s smtplib to send the emails |
GitHub Code and Datasets
GitHub: https://github.com/Bryantbrewster/RecipeRecommendationEngine
Kaggle Datasets: https://www.kaggle.com/datasets/shuyangli94/food-com-recipes-and-user-interactions?select=PP_recipes.csv
Thanks for reading!

Leave a comment